7주차 셋째날
데이터베이스 외울것도 많고 어렵다. 그래도 밥 벌어먹고 살아야하니까 잘알아야한다고 하셨다.
오전 수업시작할땐 간단한 27개 짜리 시험을 쳤다. 생각보다 많이 틀렸다. 개념을 더 공부해야겠다.
삽입, 삭제, 수정의 무결성 제약조건과 관계대수 설렉션, 프로젝션, 합집합, 교집합, 차집합, 조인을 배웠다.
간단한 쿼리문에서 ROLLBACK, delete , drop,ignore , WITH절을 배웠다.
배운점
개체 무결성 제약조건
삽입 : 기본키 값이 같으면 삽입이 금지됨.
수정 : 기본키 값이 같거나 NULL로도 수정이 금지됨.
삭제 : 특별한 확인이 필요하지 않으며 즉시 수행함.
삽입
도메인검사-> 제약조건검사 (수정할 때도)
1. 이미 501 키가 있음, 개체무결성 제약조건 위반 : 남슬찬 삽입 x
2. 기본키는 NOT NULL 이기 때문에 NULL, 남슬찬도 삽입 x

학과(부모 릴레이션) : 투플 삽입한 후 수행하면 정상적으로 진행
학생(자식 릴레이션) : 참조받는 테이블에 외래키 값이 없으므로 삽입이 금지 (예를들어 3001을 학생에 넣음)
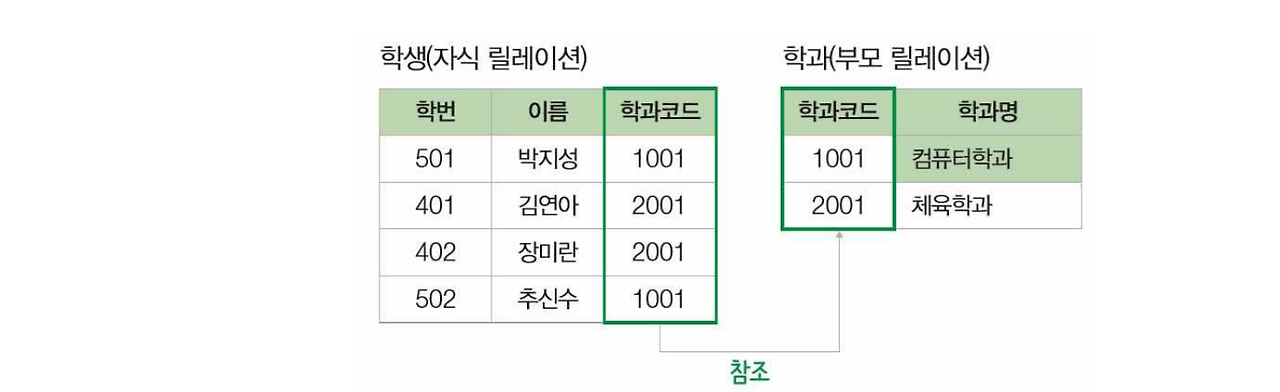
삭제
부모(학과) 함부로 못날림, 학생은 상관없음
학과(부모 릴레이션) : 참조하는 테이블을 같이 삭제할 수 있어서 금지하거나 다른 추가 작업이 필요함.
학생(자식 릴레이션) : 바로 삭제 가능함.
※ 부모 릴레이션에서 투플을 삭제할 경우 참조 무결성 조건을 수행하기 위한 고려사항
① 즉시 작업을 중지
② 자식 릴레이션의 관련 투플을 삭제
③ 초기에 설정된 다른 어떤 값으로 변경
④ NULL 값으로 설정
수정
삭제와 삽입 명령이 연속해서 수행됨.
부모 릴레이션의 수정이 일어날 경우 삭제 옵션에 따라 처리된 후 문제가 없으면 다시 삽입 제약조건에 따라 처리됨.
옵션이 있음

참조 무결성 제약조건에서 부모 릴레이션의 투플을 삭제할 경우 (부모삭제!)

관계대수(relational algebra, 關係代數)
릴레이션에서 원하는 결과를 얻기 위해 수학의 대수와 같은 연산을 이용하여 질의하는 방법을 기술하는 언어
데이터 모델:
데이터, 오퍼레이션, 제약조건
관계대수와 관계해석
관계대수 : 어떤 데이터를 어떻게 찾는지에 대한 처리 절차를 명시하는 절차적인 언어이며, DBMS 내부의 처리 언어로 사용됨, 연산(오퍼레이션)을 이용해 질의
관계해석 : 어떤 데이터를 찾는지 명시하는 선언적인 언어로 관계대수와 함께 관계 DBMS의 표준 언어인 SQL의 이론적인 기반을 제공함
→ 관계대수와 관계해석은 모두 관계 데이터 모델의 중요한 언어이며 실제 동일한 표현 능력을 가지고 있음.
관계데이터 베이스 모델
릴레이션
집합(숫자, 문자, 사람 등의 객체의 모임)
릴레이션(relation)의 수학적 개념
A = {2, 4}, B = {1, 3, 5} 일 때
AxB = {(2,1), (2,3), (2,5), (4,1), (4,3), (4,5)}
릴레이션 R은 카티전 프로덕트의 부분집합으로 정의
예) R1 = {(2,1), (4,1)}, R2={(2, 1), (2, 3), (2, 5)}, R3={(2, 3), (2, 5), (4, 3), (4, 5)}
원소 개수가 n인 집합 S의 부분집합의 개수는 2ⁿ이므로, 카티전 프로덕트 A×B의
부분집합의 개수는
카티전 프로덕트의 기초 집합 A, B 각각이 가질 수 있는 값의 범위를 도메인(domain)이라고 함. 즉 집합 A의 도메인은 {2, 4}
릴레이션 역시 집합이므로 집합에서 집합에서 가능한 연산은 합집합(∪), 교집합(∩), 카티전 프로덕트(×) 등이 있음.
R1 ∪ R2 = {(2, 1), (4, 1), (2, 3), (2, 5)}
R1 ∩ R2 = {(2, 1)}
릴레이션(relation)의 현실 세계 적용
학번={2, 4}, 과목={데이터베이스, 자료구조, 프로그래밍}일 때
두 집합의 카티전 프로덕트 학번×과목은 학번 원소와 과목 원소의 순서쌍의 집합임. 즉, 학번×과목={(2, 데이터베이스), (2, 자료구조), (2, 프로그래밍), (4, 데이터베이스), (4, 자료구조), (4, 프로그래밍)}을 말함.
2 x 3 = 6 / 학생이 과목 선택할 수 있는 모든 경우의 수
학번×과목의 각 원소는 학생이 과목을 수강할 수 있는 모든 경우를 나열한 것임. 수강={(2, 데이터베이스), (2, 자료구조), (4, 프로그래밍)}은 카티전 프로덕트 학번×과목의 부분집합으로 하나의 릴레이션 인스턴스임.
수강 릴레이션의 투플은 위에서 나열한 여섯 개 원소 중 하나로, 아래 수강 테이블을 데이터베이스에서는 릴레이션(relation)이라고 함.
=> 서로 다른 테이블을 연산을 통해 수강이라는 집합이 나왔다.
수강 릴레이션!

관계대수 연산
순수 관계연산: slelection(튜플단위), projection(컬럼단위), join, division, rename(개명)
일반 집합 연산: union, intersection, difference, cartesian product

관계대수식
관계대수는 릴레이션 간 연산을 통해 결과 릴레이션을 찾는 절차를 기술한 언어로, 이 연산을 수행하기 위한 식을 관계대수식(relational algebra expression)이라고 함.
관계대수식은 대상이 되는 릴레이션과 연산자로 구성되며, 결과는 릴레이션으로 반환됨. 반환된 릴레이션은 릴레이션의 모든 특징을 따름.
단항 연산자 : 연산자<조건> 릴레이션
이항 연산자 : 릴레이션1 연산자<조건> 릴레이션2

설렉션: A=a1 or A=a2 조건
프로젝션: A, B 속성
합집합: 중복제거 합집합
차집합: 중복 빼고 나머지
조인: R1 의 C와 R2의 C값이 같은 애들만 뽑아와라

셀렉션(selection)
WHERE 조건이라고 보면됨
릴레이션의 투플을 추출하기 위한 연산임. 하나의 릴레이션을 대상으로 하는 단항 연산자며, 찾고자 하는 투플의 조건(predicate)을 명시하고 그 조건에 만족하는 투플을 반환함.

질의 2-1 서점에서 판매하는 도서 중 8,000원 이하인 도서를 검색하시오.
• σ 가격<=8000 (도서)
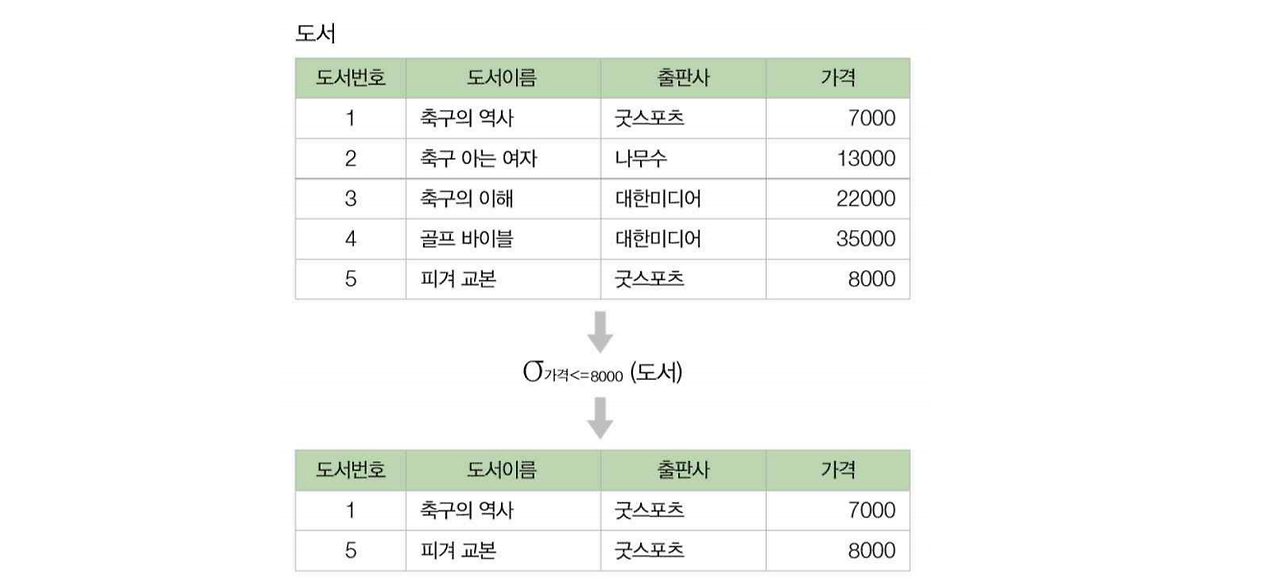
셀렉션의 확장
형식 : σ<복합조건> (R) (R은 릴레이션, σ 는 그리스 문자이며 대문자는 Σ )
여러 개의 조건을 ∧(and), ∨ (or), ┑(not) 기호를 이용하여 복합조건을 표시할 수 있다. 예를 들어, “가격이 8,000원 이하이고, 도서번호가 3 이상인 책을 찾아라”는 질의는
다음과 같이 표현한다

프로젝션(projection)
SELECT 명령어라고 보면됨
릴레이션의 속성을 추출하기 위한 연산으로 단항 연산자임. n 형식 : π<속성리스트> (R)

신간도서 안내를 위해 고객의 (이름, 주소, 핸드폰)이 적힌 카탈로그 주소록을 만드시오.
π 이름, 주소, 핸드폰 (고객)

합집합
두 개의 릴레이션을 합하여 하나의 릴레이션을 반환함. 이 때 두 개의 릴레이션은 서로 같은 속성 순서와 도메인을 가져야 함.
형식 : R ∪ S
서점은 지점A와 지점B가 있다. 두 지점의 도서는 각 지점에서 관리하며 릴레이션
이름은 각각 도서A, 도서B다. 마당서점의 도서를 하나의 릴레이션으로 보이시오.
도서A ∪ 도서B

교집합
합병가능한 두 릴레이션을 대상으로 하며, 두 릴레이션이 공통으로 가지고 있는 투플을 반환함. n 형식 : R ∩ S
서점의 두 지점에서 동일하게 보유하고 있는 도서 목록을 보이시오
도서A ∩ 도서B

차집합
첫 번째 릴레이션에는 속하고 두 번째 릴레이션에는 속하지 않는 투플을 반환함.
형식 : R - S
서점 두 지점 중 지점 A에서만 보유하고 있는 도서 목록을 보이시오
도서A - 도서B

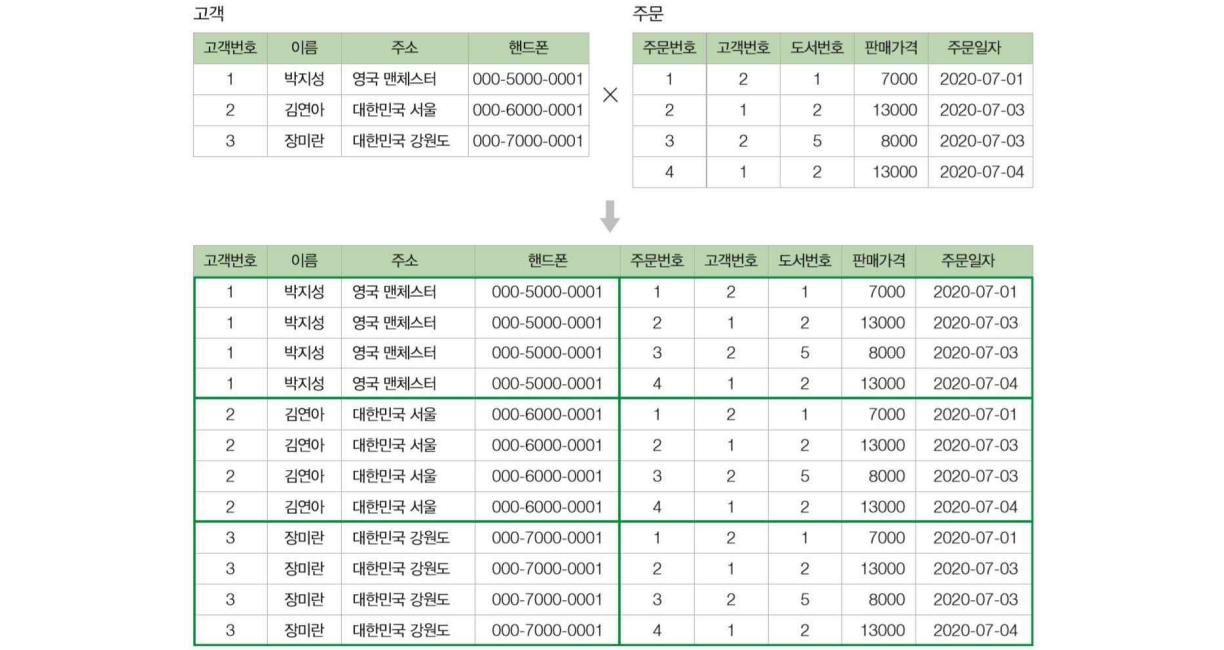
카티전 프로덕트(cartesian product)
X
두 릴레이션을 연결시켜 하나로 합칠 때 사용함. 결과 릴레이션은 첫 번째 릴레이션의 오른쪽에 두 번째 릴레이션의 모든 투플을 순서대로 배열하여 반환함. 결과 릴레이션의 차수는 두 릴레이션의 차수의 합이며, 카디날리티는 두 릴레이션의 카디날리티의 곱임
형식 : R × S
고객 릴레이션과 주문 릴레이션의 카티전 프로덕트를 구하시오
(결과가 많으므로 투플을 일부 삭제한 릴레이션을 사용함).
고객 × 주문 // 3개 x 4개 = 12개
조인(join)
양쪽에 같은 컬럼있어야함, 기준값을 줘서 기준값이 같은것들을 투플 단위로 결합해서 뽑아옴. 수평연산.
두 릴레이션의 공통 속성을 기준으로 속성 값이 같은 투플을 수평으로 결합하는 연산임. 조인을 수행하기 위해서는 두 릴레이션의 조인에 참여하는 속성이 서로 동일한 도메인으로 구성되어야 함. 조인 연산의 결과는 공통 속성의 속성 값이 동일한 투플 만을 반환함.
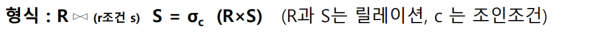
조인 연산의 구분
기본연산 : 세타조인, 동등조인, 자연조인
확장된 조인 연산 : 세미조인, 외부조인
복사해서 create 할 수 있다.
제약사항까지 복사되지는 않음
CREATE TABLE buytbl2 (SELECT * FROM buytbl);
CREATE TABLE buytbl3 (SELECT num, userID, prodName FROM buytbl);
DESC buytbl2;
GROUP BY 절 과 HAVING, 집계 함수
ID 별 구매 합
SELECT SUM(amount) AS 총개수 FROM buytbl GROUP BY userID;
전체 구매자가 구매한 물품의 평균을 구하여 조회하시오
SELECT AVG(amount) AS '평균 구매 개수' FROM buytbl ;
각 사용자 별로 한 번 구매 시 평균 몇개를 구매했는지 평균을 출력
select userID, avg(amount) from buytbl group by userID;
prodName을 추가했다. 의미가 없음 근데, userID로 묶었으니깐
select userID,prodName, avg(amount) from buytbl group by userID;
usertbl 에서 가장 큰 키와 가장 작은 키의 회원의 이름과 키 출력
select name, max(height), min(height) from usertbl;
바비킴 의미가 없음 -> 서브쿼리 이용

서브쿼리로 max, min 에 해당하는 height 출력
select name, height from usertbl where height = (select max(height) from usertbl)
or height = (select min(height) from usertbl);
휴대폰이 있는 사용자의 수를 출력하세요
단순하게 전체 카운트
select count(*) from usertbl;
근데 null도 있음

속성 지정해서 count 해줌
select count(mobile1) from usertbl;
Group by의 조건: Having
사용자별 총 구매액 출력
SELECT userID AS '사용자' , SUM(price*amount) AS '총 구매액'
FROM buytbl
GROUP BY userID;
총 구매액이 1000 이상인 사용자에게만 사은품 증정하려고 한다. 이 조건에 해당하는 사용자 아이디를 출력
where 절에서 집계함수 쓸 수 없다! , userid 별 그룹묶은 후 having 줌
select userID
from buytbl
group by userID having sum(price * amount) > 1000;
총 구매액이 1000 이상인 사용자에게만 사은품 증정하려고 한다.
이 조건에 해당하는 사용자 아이디와 총구매액이 적은순으로출력
++ order by 추가
select userID, sum(price * amount)
from buytbl
group by userID having sum(price * amount) > 1000
order by sum(price * amount);
총합 또는 중간합계를 구하려면 group by 절과 ROLLUP문을 함께 사용
select num, groupName, SUM(price * amount) as 비용 from buytbl group by groupName,num with rollup;
1,10,12 번의 소합계 : 180
7,8,11 번의 소합계 : 120..
토탈 이것을의 합 : 3500

트랜젝션
테이블의 데이터를 변경(입력/수정/삭제) 할때 실제 테이블에 완전히 적용하지 않고, 임시로 적용시키는 것. 실수가 있을 경우 취소할 수 있다.
확정하고싶으면 commit;
한 번 commit 하면 rollback으로 되돌릴 수 없다!!!
insert into usertbl values ('sym2','yoomi',2000,'기','010','12345678',170,'2024-01-17');
rollback; // 롤백
필드들을 다 넣지 않겠다.
입력안한곳은 null이 들어감
insert into testTbl1 values(1,'sss',20);
insert into testTbl1(id,userName) values(2,'kko'); -- 필드들을 다 넣지 않겠다.
insert into testTbl1(userName,id,age) values('jko',3,22);
autoincrement 어느 숫자까지 증가되었는지 확인방법
select last_insert_id();
auto_increment 입력값을 100부터 입력되도록 변경하겠다.
alter table testTbl2 auto_increment = 100;
3씩 증가함
set @@auto_increment_increment = 3;
대량의 샘플데이터 생성방법 : insert into ... select 구문
create table testTbl3 (id int, Fname varchar(56), Lname varchar(50));
insert into testTbl3
select emp_no,first_name,last_name from employees.employees;
testTb14 employees.employees 테이블 속성 중 emp_no, first_name, last_name
create table testTbl4 (select emp_no, first_name, last_name from employees.employees);
데이터의 수정 : UPDATE : 기존에 입력되어 있는 값을 변경하기 위해 사용하는 명령어
UPDATE 테이블 이름
SET 열1 = 값1, 열2 = 값2
WHERE 조건; -- 생략가능
update testTbl4
set last_name = 'none'
where first_name = 'Kyoichi';
데이터의 삭제 : DELETE FROM
튜플 단위
DELETE FROM 테이블이름 WHERE 조건 (행, ROW, Tuple) 단위로 삭제
delete from testTbl4
where first_name = 'Berni';
// limit 5 사용 상위 5명 삭제
delete from testTbl4
where first_name = 'Berni' limit 5;
전체 튜플 삭제
검색하면 검색 됨
delete from bigTbl1;
테이블 구조 삭제
검색되지 않음
drop table bigTbl2;
빠른 전체 튜플 삭제
delete와 동일하나 트랜잭션 로그를 기록하지 않아 속도가 빠르다.
truncate table bigTbl3;
userTbl에서 아이디, 이름, 주소 만 가지고 와서 memberTBL 생성하시오. 3건만 가져오기
limit 사용
create table memberTBL(select userID, name, addr from userTbl limit 3);
primary key 추가
alter Table memberTBL ADD constraint pk_memberTBL primary key (userID);
ignore
로그만 남기고 stop하지않고 그냥 다음꺼진행시킴 , mysql만 가능
insert ignore into memberTBL values('BBQ','비비큐','한국');
on duplicate key update
중복이 되면 , 내용을 수정하겠다. 중복이 아니면 , 일반 insert와 같다.
insert ignore into memberTBL values('BBQ','비비큐_간장치킨','한국')
on duplicate key update name = '비비큐_간장치킨', addr = '미국';
WITH 절
CTE( Common Table Expression)를 표현하기 위한 구문 MYSQL의 8.0 이후 사용가능
재귀적 CTE
with CTE_테이블명(열이름 ..., )
AS
(쿼리문) SELECT 열 이름 FROM CTE_테이블이름;
buytbl에서 사용자 아이디별 총 구매액을 출력
서브쿼리의 출력을 각각 abc(userid, total)에 매핑시킨다. 그리고 from abc해서 total 기준으로 내림차순 정렬함.
abc라는 테이블이 만들어졌다.
with abc(userid, total) // CTE 테이블 ! 만든거 !!
as (SELECT userid, sum(price * amount)
from buytbl group by userid) select * from abc order by total desc;
회원테이블(userTBL) 에서 각 지역별로 가장 큰 키를 가진 회원1명을 뽑은 후에, 그 사람들의 평균을 구하여 출력
-- 1. 각 지역별 큰 키를 가진 회원 조회하기
SELECT addr, max(height) from usertbl group by addr;
-- 2. WITH 절에 넣기
WITH height_user(addr, maxHeight)
as (SELECT addr, max(height) from usertbl group by addr)
SELECT avg(maxHeight * 1.0) as '각 지역별 최고키의 평균' from height_user;
회고
시험을치니 생각보다 어려웠다. 나름 어제 개념복습을 했는데 확실치 않는갑다.
사실 안 배운부분도있었는데 처음으로 오답노트를 정리하니 부족했던 부분을 좀 채웠다.
NOT BETWEEN ~ AND ~ 를알았고, alias는 GROUP BY절 이후부터 사용이 가능했다.
데이터 베이스의 네가지 특징, 실시간 데이터 접근, 지속적인 데이터 업데이트, 값으로 데이터 참조, 여러 사용자 동시에 사용할 수있다.
WITH절을 처음봤다. mysql 8.0 부터 나왔다고 하는데 왜 처음보는지모르겠다.
함수 처럼 쿼리문에 이름을 정하고 결과 테이블을 사용하는게 신기하고 간편하다고 생각했따. 또 하나 알아간다.
'신세게 - Java 공부' 카테고리의 다른 글
| 7주차 배운점 느낀점 - sql 문제, 내장 함수, view, index, 물리적 저장 (8) | 2024.10.05 |
|---|---|
| 7주차 배운점 느낀점 - join, Outer join, MINUS, INTERSECT, EXISTS (1) | 2024.10.05 |
| 7주차 배운점 느낀점 - KEY, CONSTRAINT, 릴레이션, 데이터 무결성 (5) | 2024.10.05 |
| 7주차 배운점 느낀점 - 데이터베이스, DBMS, SQL, SELECT, WHERE (10) | 2024.10.05 |
| 6주차 배운점 느낀점 - 운영체제, Thread, 스레드 상태, Synchronized (2) | 2024.10.05 |



